Julian Andres Klode: APT 1.5 is out
APT 1.5 is out, after almost 3 months the release of 1.5 alpha 1, and almost six months since the release of 1.4 on April 1st. This release cycle was unusually short, as 1.4 was the stretch release series and the zesty release series, and we waited for the latter of these releases before we started 1.5. In related news, 1.4.8 hit stretch-proposed-updates today, and is waiting in the unapproved queue for zesty.
This release series moves https support from apt-transport-https into apt proper, bringing with it support for https:// proxies, and support for autodetectproxy scripts that return http, https, and socks5h proxies for both http and https.
Unattended updates and upgrades now work better: The dependency on network-online was removed and we introduced a meta wait-online helper with support for NetworkManager, systemd-networkd, and connman that allows us to wait for network even if we want to run updates directly after a resume (which might or might not have worked before, depending on whether update ran before or after network was back up again). This also improves a boot performance regression for systems with rc.local files:
The rc.local.service unit specified After=network-online.target, and login stuff was After=rc.local.service, and apt-daily.timer was Wants=network-online.target, causing network-online.target to be pulled into the boot and the rc.local.service ordering dependency to take effect, significantly slowing down the boot.
An earlier less intrusive variant of that fix is in 1.4.8: It just moves the network-online.target Want/After from apt-daily.timer to apt-daily.service so most boots are uncoupled now. I hope we get the full solution into stretch in a later point release, but we should gather some experience first before discussing this with the release time.
Balint Reczey also provided a patch to increase the time out before killing the daily upgrade service to 15 minutes, to actually give unattended-upgrades some time to finish an in-progress update. Honestly, I d have though the machine hung up and force rebooted it after 5 seconds already. (this patch is also in 1.4.8)
We also made sure that unreadable config files no longer cause an error, but only a warning, as that was sort of a regression from previous releases; and we added documentation for /etc/apt/auth.conf, so people actually know the preferred way to place sensitive data like passwords (and can make their sources.list files world-readable again).
We also fixed apt-cdrom to support discs without MD5 hashes for Sources (the Files field), and re-enabled support for udev-based detection of cdrom devices which was accidentally broken for 4 years, as it was trying to load libudev.so.0 at runtime, but that library had an SONAME change to libudev.so.1 we now link against it normally.
Furthermore, if certain information in Release files change, like the codename, apt will now request confirmation from the user, avoiding a scenario where a user has stable in their sources.list and accidentally upgrades to the next release when it becomes stable.
Paul Wise contributed patches to allow configuring the apt-daily intervals more easily apt-daily is invoked twice a day by systemd but has more fine-grained internal timestamp files. You can now specify the intervals in seconds, minutes, hours, and day units, or specify always to always run (that is, up to twice a day on systemd, once per day on non-systemd platforms).
Development for the 1.6 series has started, and I intent to upload a first alpha to unstable in about a week, removing the apt-transport-https package and enabling compressed index files by default (save space, a lot of space, at not much performance cost thanks to lz4). There will also be some small clean ups in there, but I don t expect any life-changing changes for now.
I think our new approach of uploading development releases directly to unstable instead of parking them in experimental is working out well. Some people are confused why alpha releases appear in unstable, but let me just say one thing: These labels basically just indicate feature-completeness, and not stability. An alpha is just very likely to get a lot more features, a beta is less likely (all the big stuff is in), and the release candidates just fix bugs.
Also, we now have 3 active stable series: The 1.2 LTS series, 1.4 medium LTS, and 1.5. 1.2 receives updates as part of Ubuntu 16.04 (xenial), 1.4 as part of Debian 9.0 (stretch) and Ubuntu 17.04 (zesty); whereas 1.5 will only be supported for 9 months (as part of Ubuntu 17.10). I think the stable release series are working well, although 1.4 is a bit tricky being shared by stretch and zesty right now (but zesty is history soon, so ).
Filed under: Debian, Ubuntu
Filed under: Debian, Ubuntu


 And, for those of you who don t know: uberspace is a shared hoster that basically just gives you an SSH shell account, directories for you to drop files in for the http server, and various tools to add subdomains, certificates, virtual users to the mailserver. You can also run your own custom build software and open ports in their firewall. That s quite cool.
I m considering migrating the blog away from wordpress at some point in the future having a more integrated experience is a bit nicer than having my web presence split over two sites. I m unsure if I shouldn t add something like cloudflare there I don t want to overload the servers (but I only serve static pages, so how much load is this really going to get?).
in other news: off-site backups
I also recently started doing offsite backups via borg to a server operated by the wonderful
And, for those of you who don t know: uberspace is a shared hoster that basically just gives you an SSH shell account, directories for you to drop files in for the http server, and various tools to add subdomains, certificates, virtual users to the mailserver. You can also run your own custom build software and open ports in their firewall. That s quite cool.
I m considering migrating the blog away from wordpress at some point in the future having a more integrated experience is a bit nicer than having my web presence split over two sites. I m unsure if I shouldn t add something like cloudflare there I don t want to overload the servers (but I only serve static pages, so how much load is this really going to get?).
in other news: off-site backups
I also recently started doing offsite backups via borg to a server operated by the wonderful 

 I m proud (yes, really) to announce DNS66, my host/ad blocker for Android 5.0 and newer. It s been around since last Thursday on F-Droid, but it never really got a formal announcement.
DNS66 creates a local VPN service on your Android device, and diverts all DNS traffic to it, possibly adding new DNS servers you can configure in its UI. It can use hosts files for blocking whole sets of hosts or you can just give it a domain name to block (or multiple hosts files/hosts). You can also whitelist individual hosts or entire files by adding them to the end of the list. When a host name is looked up, the query goes to the VPN which looks at the packet and responds with NXDOMAIN (non-existing domain) for hosts that are blocked.
You can find DNS66 here:
I m proud (yes, really) to announce DNS66, my host/ad blocker for Android 5.0 and newer. It s been around since last Thursday on F-Droid, but it never really got a formal announcement.
DNS66 creates a local VPN service on your Android device, and diverts all DNS traffic to it, possibly adding new DNS servers you can configure in its UI. It can use hosts files for blocking whole sets of hosts or you can just give it a domain name to block (or multiple hosts files/hosts). You can also whitelist individual hosts or entire files by adding them to the end of the list. When a host name is looked up, the query goes to the VPN which looks at the packet and responds with NXDOMAIN (non-existing domain) for hosts that are blocked.
You can find DNS66 here:


 If you want, sicherboot automatically creates db, KEK, and PK keys, and puts the public keys on your EFI System Partition (ESP) together with the KeyTool tool, so you can enroll the keys in UEFI. You can of course also use other keys, you just need to drop a db.crt and a db.key file into
If you want, sicherboot automatically creates db, KEK, and PK keys, and puts the public keys on your EFI System Partition (ESP) together with the KeyTool tool, so you can enroll the keys in UEFI. You can of course also use other keys, you just need to drop a db.crt and a db.key file into 


 In 2016-06-18:
In 2016-06-18:
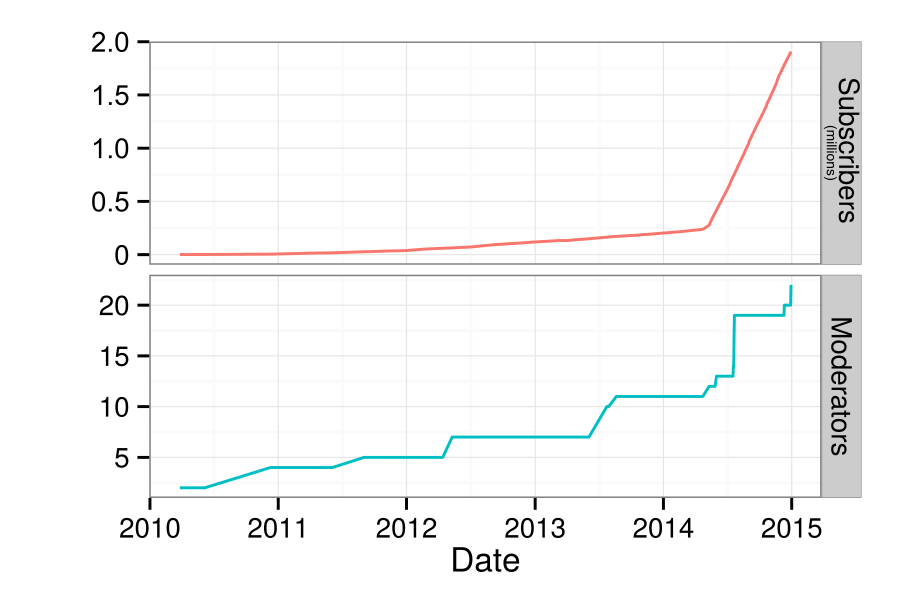
 Numbers
The
Numbers
The 


 What happened in the
What happened in the 